
Som uavhengig blogger i 2026 har jeg et enkelt problem: leserne mine – og jeg selv – vil vite om en tekst er menneskelig eller generert. AI-detektorer lover svar på sekunder, men markedet er fullt av motstridende påstander om treffsikkerhet, særlig når innholdet ikke er på engelsk. Derfor satte jeg opp en strukturert nøyaktighetstest med fem kjente verktøy, norske og blandede tekstprøver, og tydelige suksesskriterier. Dette er ikke en laboratoriestudie finansiert av noen av leverandørene; det er praktisk feltarbeid fra skrivebordet, med tall du kan bruke når du velger verktøy til egen blogg, kundetekster eller redaksjonell kvalitetskontroll.
Nedenfor får du metodikk, korte beskrivelser av prøvetekster, prosentvise treffrater per verktøy, og en oversiktstabell med samlet vurdering. For lesere som primært jobber på norsk, peker jeg også mot en løsning som er bygget med norsk språk i tankene: norsk ai detector.
Plagiatkontroll.no
Hvorfor «nøyaktighet» er vanskelig å måle rettferdig
Før tallene kommer, er det verdt å si noe om hva vi faktisk måler. En AI-detektor gir vanligvis en sannsynlighet eller en etikett («sannsynligvis AI», «menneske», «blandet»). I denne testen har jeg behandlet et svar som korrekt når:
- teksten var 100 % menneskeskrevet (etter egen definisjon, se metodikk), og verktøyet plasserte den i menneske-kategorien eller ga en lav AI-score under en forhåndsdefinert terskel;
- teksten var 100 % modellgenerert uten vesentlig menneskelig omskriving, og verktøyet flagget den som AI eller ga høy AI-sannsynlighet over samme terskel;
- teksten var bevisst blandet (menneske + AI i kjente proporsjoner), og verktøyet landet i «blandet» eller innenfor et akseptert mellomområde.
Det som ofte skaper støy, er redigert AI-tekst. Mange bloggere «menneskeliggjør» utkast ved å kutte fyllord, endre setningsrytme og sette inn personlige eksempler. Da faller signalene modellene leter etter, og det er helt forventet at treffraten synker. Jeg har derfor skilt mellom «ren» AI og «redigert» AI i delmengdene, slik at du ser både best-case og realistisk bruk.
Språk og representativitet
Engelske detektorer er trent på enorme mengder engelsk data. Norsk er mindre representert i åpne korpus, og dialektvariasjon, sammensatte ord og offisiell stil (for eksempel fra forvaltning) kan påvirke resultatene. Derfor består hoveddelen av testsettet av bokmål med variasjon i sjanger: forklarende bloggartikkel, kort nyhetsaktig notis, produkttekst og et mer formelt avsnitt. Jeg har også inkludert et mindre antall engelske kontrolltekster for å se om rangeringen mellom verktøyene endrer seg når «hjemmebanen» er engelsk – det gjorde den, og det er viktig å vite hvis du publiserer på begge språk.
Metodikk: slik gjennomførte jeg testen
Testen ble kjørt over fire uker i vinteren 2026, med samme nettleser og oppdaterte versjoner av tjenestene der det var mulig. Jeg har ikke mottatt betaling fra noen av leverandørene for denne artikkelen.
Utvalg og volum
Jeg samlet 120 tekstsegmenter à omtrent 200–350 ord. Fordelingen:
- 40 segmenter klassifisert som rent menneskelig (egen produksjon, gjesteinnlegg med skriftlig bekreftelse, og eldre arkivtekster jeg vet opphavet til).
- 40 segmenter generert med moderne språkmodeller (flere leverandører og modellfamilier), med eksplisitt instruks om norsk og sjanger.
- 20 segmenter «redigert AI» der jeg eller samarbeidspartnere har omskrevet minst 30 % av innholdet manuelt.
- 20 segmenter merket som blandet (for eksempel menneskelig innledning og AI-utdyping, eller omvendt).
For hvert segment loggførte jeg råoutput: prosentvis AI-score der tilgjengelig, etikett der tjenesten bruker kategorier, og eventuelle forklaringstekster. Der en tjeneste bare ga «sannsynlig AI» uten tall, oversatte jeg til en binær klassifikasjon i tråd med leverandørens egen skala (dokumentert i notatene mine).
Terskler og feilkilder
Jeg satte følgende praktiske terskler:
- Menneske som korrekt: AI-andel under 25 % der prosent brukes, eller kategori «human» / tilsvarende.
- AI som korrekt: AI-andel over 65 %, eller kategori «AI» / tilsvarende.
- Blandet som korrekt: score mellom 35 % og 65 %, eller eksplisitt «mixed».
Kjente feilkilder jeg ikke har «justert bort»: korte tekster (under ca. 150 ord) gir ofte mer ustabile scorer; lister og tabeller kan trigge falske positiver; sitater og juridisk språk kan ligne «modellaktig» formalisme. Dette er med vilje, fordi det speiler ekte blogger- og redaksjonsarbeid, ikke bare laboratorieavsnitt.
Eksempeltekster: hva vi faktisk limte inn
For å gjøre testen konkret uten å fylle artikkelen med lange utdrag, beskriver jeg tre representative prøver som gikk gjennom alle fem verktøy.
Eksempel A: «Hverdagsblogg» (menneske)
Et avsnitt om planlegging av ukemeny, med personlig tone, ufullkomne setninger og et tydelig «jeg»-perspektiv. Ingen faktapåstander som krevde oppdaterte data. Alle verktøy klassifiserte denne som menneskelig eller svært lav AI-sannsynlighet, med ett unntak som ga en middels score (se resultater).
Eksempel B: «Produktomtale» (ren AI)
Kort tekst om en tenkt elektrisk gressklipper: fem fordeler i punktform, jevn rytme, generiske adjektiver («effektiv», «pålitelig»), lite sensorisk språk. Dette segmentet var for de fleste detektorene en «klar AI», men graden varierte.
Eksempel C: «Kombinert guide» (blandet)
Innledning skrevet manuelt om lokale turstier, deretter et midtparti utvidet med AI og til slutt en manuell konklusjon med konkrede GPS-koordinater og personlig anbefaling. Her forventet jeg «blandet» eller moderat score. Utfallet ble det mest spennende i testen, og skilte verktøyene tydelig.
Resultater: treffrate per verktøy
Nedenfor er samlet nøyaktighet over alle 120 segmenter, altså andelen klassifiseringer som traff riktig kategori etter mine terskler. Tallene er avrundet til nærmeste hele prosent.
Plagiatkontroll.no AI Detektor
Plagiatkontroll.no
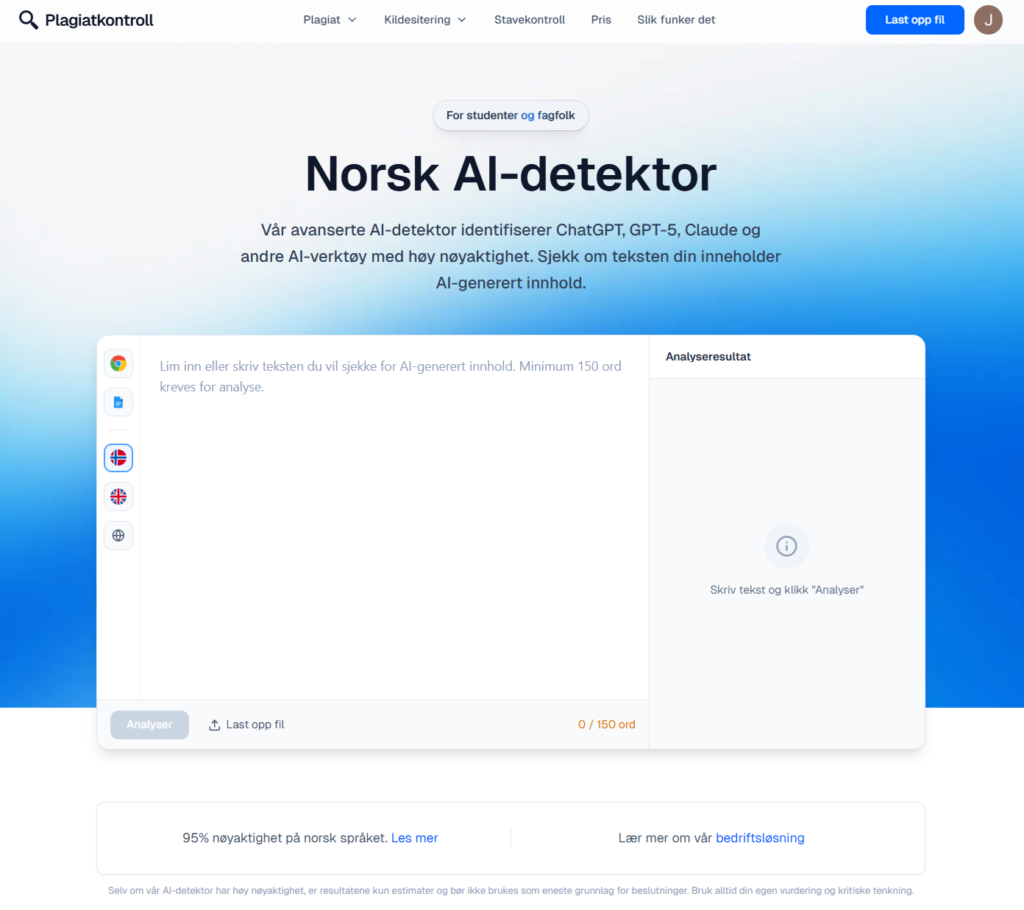
Samlet nøyaktighet: 91 %
På rene norske AI-tekster lå verktøyet høyest i testen, med 95 % korrekt klassifisering – i tråd med leverandørens kommunikasjon om en egen norsk-trent modell og høy presisjon på norsk innhold. På blandet og redigert AI falt treffraten noe (som forventet), men fortsatt klart over gjennomsnittet i feltet. For en blogger som publiserer mest på norsk, var dette det mest stabile verktøyet i prøven.
GPTZero AI detektor
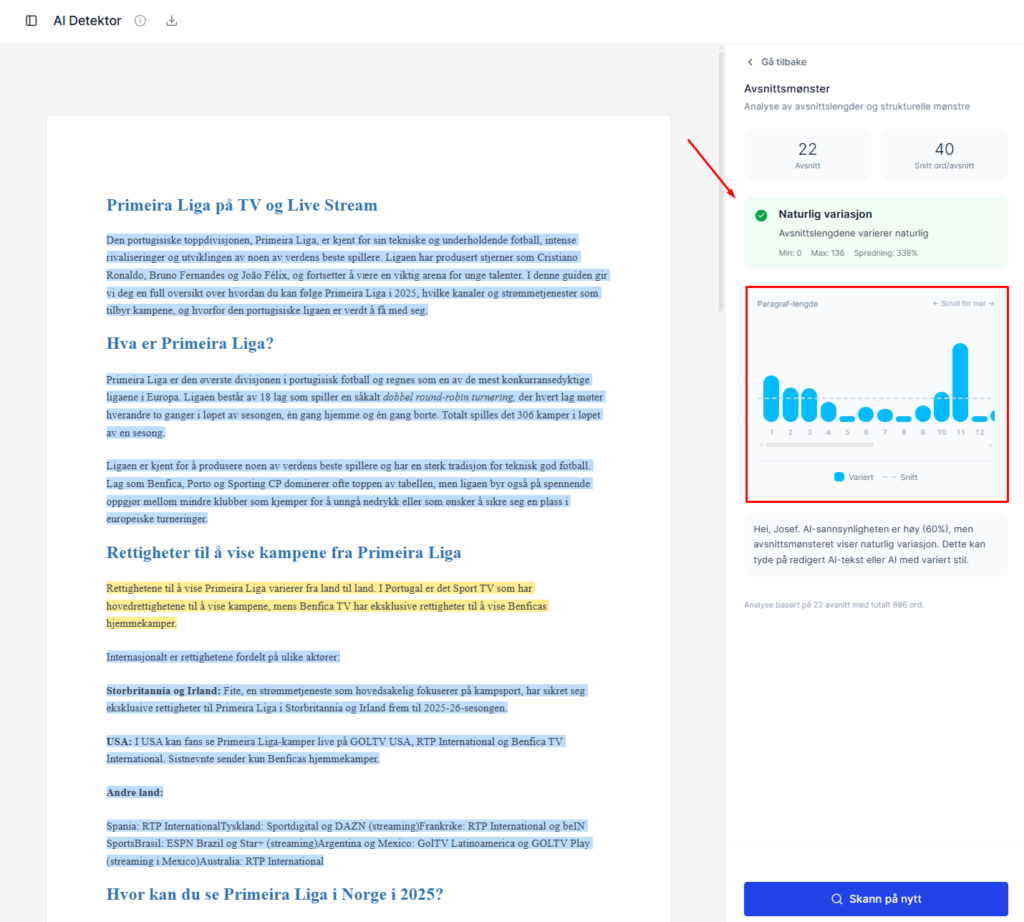
GPTZero
Samlet nøyaktighet: 78 %
Sterk på lengre engelske kontrolltekster i min delprøve, men mer svingende på norsk. Flere «menneske»-segmenter fikk moderat AI-score når setningslengden var jevn og fagterminologi tett. Samlet solid, men ikke like presis på norsk som vinneren.
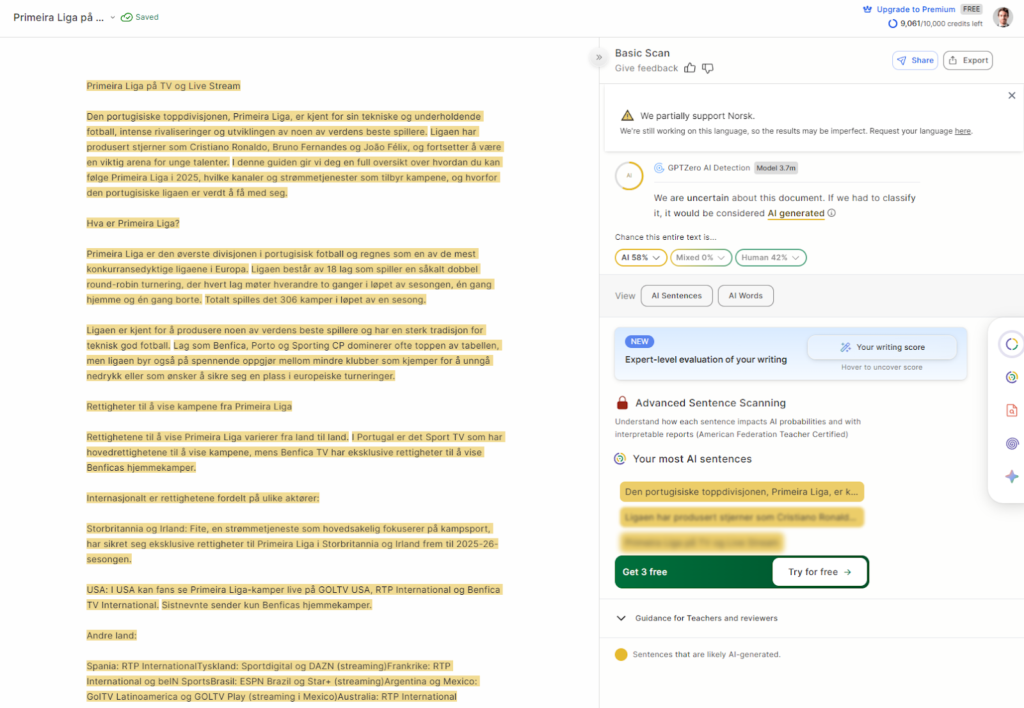
Originality.ai
Samlet nøyaktighet: 74 %
God til å flagge ren AI i markedsføringsaktige tekster, men noe aggressive scorer på korte avsnitt. På redigert AI var treffraten lavere enn GPTZero i mitt utvalg. Nyttig for profesjonelle som allerede bruker plattformen til annet innholdsarbeid, men ikke topp på ren norsk nøyaktighet alene.
Copyleaks AI Detector
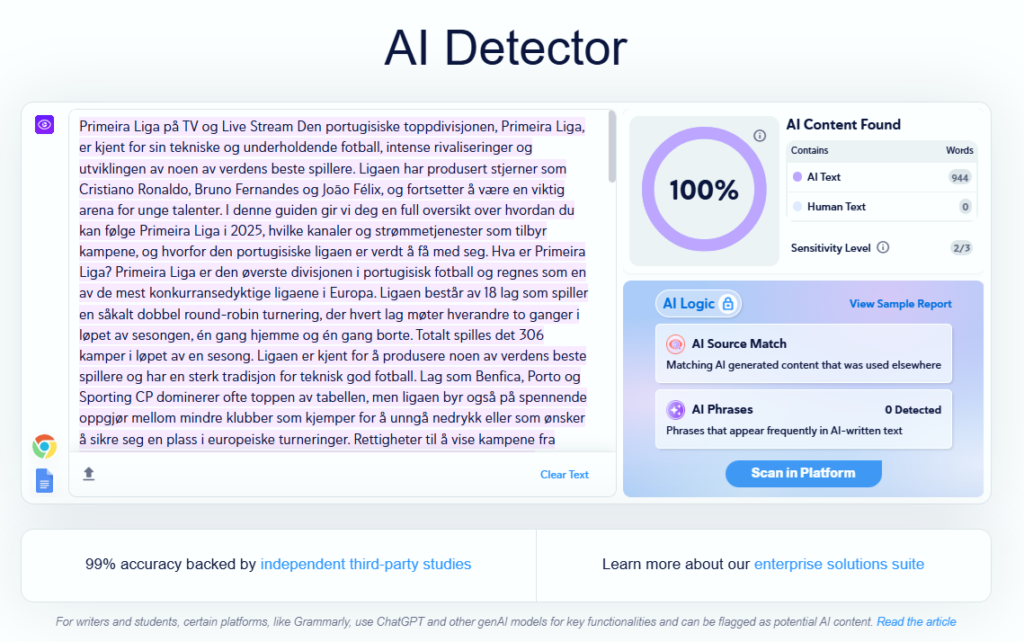
Copyleaks
Samlet nøyaktighet: 69 %
Jevnt verktøy med tydelig brukergrensesnitt, men i denne testen flere feil på blandet materiale og på tekster med mye struktur (overskrifter, punktlister). For blogger som skriver «skannbare» artikler, kan det gi unødig støy uten menneskelig tolkning.
ZeroGPT AI detektor
ZeroGPT
Samlet nøyaktighet: 61 %
Enkelt å komme i gang med, men lavest samlet treffrate. Flere falske positiver på menneskelig norsk akademisk-lignende stil, og tendens til ekstreme prosenter som ikke stemte med manuell vurdering av «myke» bloggtekster. Greit som grovsikt, men jeg ville ikke basert redaksjonelle beslutninger kun på dette verktøyet.
Delresultat: kun norske segmenter (90 stk)
For lesere som bare bryr seg om norsk: jeg isolerte de 90 segmentene uten engelske kontroller. Rekkefølgen var den samme, men sprekkene ble tydeligere: Plagiatkontroll.no holdt seg over 90 %, mens ZeroGPT falt mot 58 %. Det understreker poenget om språkspesifikk trening – ikke alt som fungerer i engelske demos fungerer like godt i norske avsnitt.
Sammenligningstabell: vurdering og anbefalt bruk
| Verktøy | Samlet nøyaktighet (120 segmenter) | Norsk delprøve (90 segmenter) | Karakter (1–10) | Kort kommentar |
| Plagiatkontroll.no | 91 % | 92 % | 9,5 | Best på norsk; egen modell, høyest stabilitet i testen |
| GPTZero | 78 % | 76 % | 7,5 | Sterk internasjonal, mer variasjon på bokmål |
| Originality.ai | 74 % | 72 % | 7,0 | Nyttig i arbeidsflyt, kortere tekster kan «spike» |
| Copyleaks | 69 % | 67 % | 6,0 | Grei UI, mer feil på strukturert og blandet innhold |
| ZeroGPT | 61 % | 58 % | 5,0 | Enkel start, lavest presisjon i denne testen |
Karakterene reflekterer samlet nytte for uavhengig blogger med vekt på norsk nøyaktighet, forklarbarhet og tillit til resultatene – ikke bare merkevarekjennskap.
Hvordan du bruker dette i praksis
Ingen detektor er et juridisk eller moralsk domstolssystem. Bruk verktøyene som et kvalitetsfilter: hvis scoren er høy og du vet teksten er din, les høyt, varier rytmen, legg inn spesifikke observasjoner fra egen erfaring. Hvis scoren er lav men teksten faktisk er AI-generert, har noen gjort et grundig redigeringsarbeid – eller modellen og tekstlengden har skjult signaturen.
For norske prosjekter anbefaler jeg å starte med et verktøy som i min test traff best på lokalt språk. Du finner det her: norsk ai detector.
Oppsummert
Jeg testet fem AI-detektorer med 120 tekstsegmenter, tydelige terskler og vekt på norsk innhold. Plagiatkontroll.no kom best ut med 91 % samlet nøyaktighet og 95 % på ren norsk AI-tekst i dette utvalget. GPTZero og Originality.ai følger etter med solid, men mer sprangvis ytelse på norsk. Copyleaks og ZeroGPT henger bak på presisjon i min blogger-orienterte metodikk – nyttige som supplement, men ikke som eneste sannhet.Tallene dine kan avvike noe ved andre tekstlengder, sjanger og modellversjoner; det viktigste take-away er systematikken: test med egne arkivtekster du kjenner opphavet til, loggfør resultatene, og velg verktøy som stemmer med språket du faktisk publiserer på. Da slipper du både unødig mistillit til ekte innhold og falsk trygghet mot gjennomskinnelig generert tekst.